

Transformer简介
Transformer结构来源于谷歌2017年的论文《Attention is All You Need》,它的出现引发了BERT系列模型不断刷新NLP领域SOTA的壮举,包括BERT、RoBERTa、ALBERT、SpanBERT、DistilBERT、SesameBERT、SemBERT、MobileBERT、TinyBERT 和 CamemBERT等等都是基于Transformer和其自注意力self-Attention展开的工作。
Transformer的网络架构由且仅由self-Attenion和Feed Forward Neural Network组成,没有用到传统的CNN或者RNN,一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建。正因如此,Transformer成为继CNN和RNN之后又一个高效的特征提取器。

什么是注意力机制?
Attention的思路,简单用四个字“带权求和”就可以高度概括,或者说在不同的上下文语境中,关注到不同的信息。Attention的思想最早于2015年的ICLR《Neural machine translation by jointly learning to align and translate》提出,后来在NLP、CV遍地开花。Attention 赋予模型区分辨别能力,从纷繁的信息中找到应当focus的重点。
Attention的出现就是为了两个目的:
- 减小处理高维输入数据的计算负担,通过结构化的选取输入的子集,降低数据维度。
- “去伪存真”,让任务处理系统更专注于找到输入数据中显著的与当前输出相关的有用信息,从而提高输出的质量。
从最早的Attention被提出之后,后面又以其为基础,衍生出了例如Bagdanau attention、 Luong attention、 self-attention、 multi-head attention等等,用面向对象的思想可以理解为Attention是基类,其他的都是对其继承和重写。
从数学角度上来理解,Attention其实就是不同单词对应的概率分布。换句话说,Attention机制是一种根据某些规则或者某些额外信息(query)从向量表达集合(values)中抽取特定的向量进行加权组合(Attention)的方法。简单来讲,只要我们从部分向量里面搞了加权求和,那就算用了Attention。
通常来说,可以用以下公式来表示:
$$\alpha=softmax(e)$$
$$a=\sum\alpha_ih_i$$
其中:
- $\alpha_i$ 指的是得分softmax之后的向量的第i个分量
- $e$ 代表的就是$attention-score$
- $attention-score$ 又有各种不同的计算方式,包括乘法、点积、加法等等
- $a$ 就是context vector(上下文向量)
Attention内容繁多,本文就不展开具体描述,主要介绍Self-Attention。
为什么需要Transformer?
在NLP任务中,通常我们会想到RNN和其延伸的LSTM、GRU等特征提取器,当然也有一些使用CNN的研究。但是无论是RNN或者CNN都有着难以弥补的缺陷。
- 语义特征提取能力:
- Transformer在这方面的能力非常显著地超过RNN和CNN(在考察语义类能力的任务WSD中,Transformer超过RNN和CNN大约4-8个绝对百分点),RNN和CNN两者能力差不太多。
- 长距离特征捕获能力:
- 原生CNN特征抽取器在这方面极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型(尤其在主语谓语距离小于13时),能力由强到弱排序为Transformer>RNN>>CNN
- 但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer
- CNN通过增大卷积核的kernel size,同时加深网络深度,可以一定程度提升
- 任务综合特征抽取能力:
- Transformer综合能力要明显强于RNN和CNN
- 并行计算能力及运行效率
- RNN在并行计算方面有严重缺陷,这是它本身的序列依赖特性导致的,线性序列依赖性非常符合解决NLP任务,但这也是无法进行并行计算的原因
- 对CNN和Transformer来说,因为它们不存在网络中间状态不同时间步输入的依赖关系,所以可以非常方便及自由地做并行计算
- Transformer和CNN差不多,都远远强于RNN
综上来看,Transformer在特征提取的上对CNN和RNN有着强大的优势。
Transformer的结构和特性
宏观来看,Transformer的本质上是一个Encoders-Decoders构成的Seq2Seq结构。
Encoders
Encoders又由若干Encoder组成,默认是6个,Decoders的设置也一样。
每个Encoder层由包括两个sub-layers,它们都模拟了残差网络的结构但没有共享参数。:
1 )第一个sub-layer是multi-head self-Attenion mechanism,用来计算输入的self-attention;
2 )第二个sub-layer是简单的全连接网络构成的Feed Forward Neural Network。
Decoders
Decoder有N(默认是6)层,每层包括三个sub-layers,多了一个Encoder-Decoder Attention:
1 )第一个是Masked multi-head self-attention,也是计算输入的self-attention,但是因为是生成过程,因此在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask.
2 )第二个sub-layer是对encoder的输入进行attention计算,这里仍然是multi-head的attention结构,只不过输入的分别是decoder的输入和encoder的输出。
3 )第三个sub-layer是全连接网络,与Encoder相同。

Transformer中的3种注意力
Transformer 框架中 self-attention 本身是一个很大的创新,然而在Encoder和Decoder中,self-attention有些许的不同。
- Encoder self-attention:Encoder 阶段捕获当前 word 和其他输入词的关联;
- MaskedDecoder self-attention :Decoder 阶段捕获当前 word 与已经看到的解码词之间的关联,从矩阵上直观来看就是一个带有 mask 的三角矩阵;
- Encoder-Decoder Attention:就是将 Decoder 和 Encoder 输入建立联系,和之前那些普通 Attention 一样;

残差结构和层归一化

在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个层归一化(具体LN的原理和可以参考Layer Normalizations)步骤,整个操作可以由以下公式表示:
$$Layer Normalizations(Residual+LayerOutput)$$
在Transformer中,每个单词都被转化为512维word-embedding,将输入序列进行词嵌入之后,每个单词都会流经编码器中的两个子层。在Self-Attention中,这些路径之间存在依赖关系,而Feed-Forward层没有这些依赖关系,此时可以并行执行。
Transformer中的Positional Encoding
在上述的编码器译码器和self-attention中,并没有包括word的位置信息,但是一句话中词语在不同的位置显然有不同的语义。
因此,在Transformer中引入位置编码:构造一个跟输入word-embedding维度一样的矩阵,然后跟输入word-embedding相加得到multi-head attention的输入。
位置编码的公式如下:
$$PE(pos,2i) = sin(pos / 10000^{2i/d_{model}})$$
$$PE(pos,2i+i) = cos(pos / 10000^{2i/d_{model}})$$
Self-Attenion的计算过程
Transformer中Self-Attenion的计算过程称为“scaled dot-product attention”:
$$Attension(Q,K,V)=softmax({QK^T\over \sqrt{d_k}})V$$
Step1-生成Query, Key, Value三个向量
首先将word转化为one-hot编码,然后将one-hot转化为Word-Embedding,通常在Pytorch中可以使用nn.Embedding函数得到,在Transformer中默认转化为512维的Word-Embedding,然后将Word-Embedding加上Positional encoding得到Embedding with posision,这个就是我们的Self-Attention的输入。
Embedding with posision乘上训练得到的$W^Q$、$W^K$、$W^V$可以得到我们所需要的$Q、K、V$向量。
Step2-计算Score、Softmax、加权和
- score为q和k的向量积$Score=q·k$
- 除以8,作者的解释是说防止$d_k$增大时,点积值过大,所以对其进行缩放。(因为这些向量的维度是64,8是开方)
- 经过softmax
- 对加权值向量求和
这样Self-Attenion的计算就完成了,得到的结果Feed Forward。在实际操作中,这些计算是以矩阵并行操作完成的。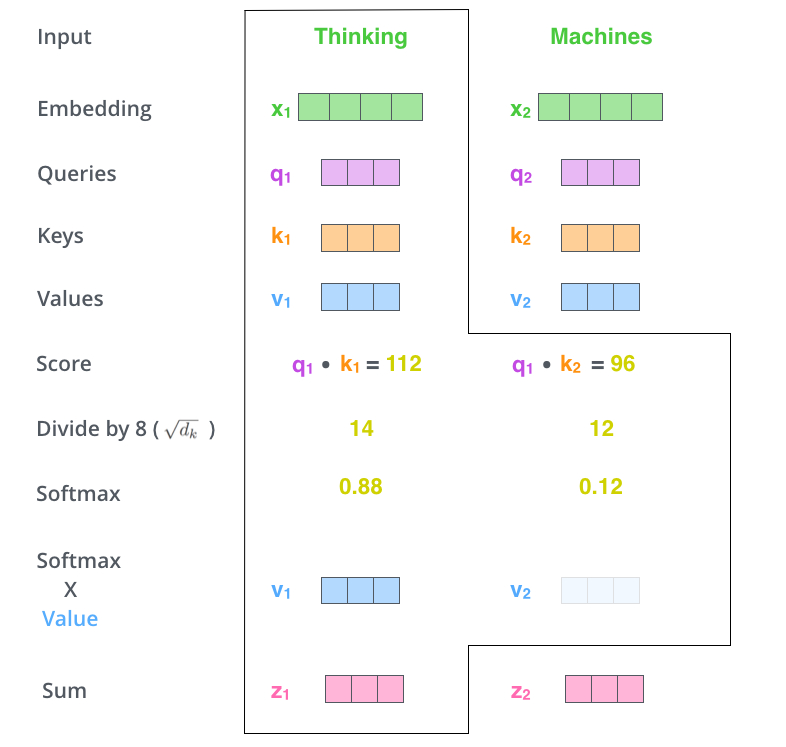

最终,总结下Self-Attenion输出的计算过程就是这个公式:
Multi-Heade Attention机制
多头(Multi-Heade Attention)即为自注意力(Self-Attention)组成的一个结构,默认为8个Self-Attention组成。
多头机制能在两个方面提升注意力层的性能:
- 它扩展了模型专注于不同位置的能力。
- 它给出了注意力层的多个“表示子空间”(representation subspaces)。
在“多头”注意机制下,我们计算得出8个self-Attentions的结果矩阵 $Z_i$ (计算过程在上文Self-Attention已详细介绍),然后将 $Z_0,Z_1,…,Z_7$ 共8个矩阵拼接起来乘上权重矩阵$W^O$就得到最终的矩阵 $Z$ 传递给Feed Forward 层,具体过程如下图所示。
模型输出
Decoder的输出经过一层全联接网络和softmax。
得到最终的结果,映射为每个位置对应的词的概率分布。
Transformer总结
整个Transformer的工作流程可以从下图清晰地看出。
优点:
- 虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
- 2.Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
- Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
- 算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:
- 粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
- Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
Reference
本文参考了以下几篇文章,仅供学习交流。
- The Illustrated Transformer
- 一步步解析Attention is All You Need!
- 放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较
- 详解Transformer (Attention Is All You Need)
- 自然语言处理中的Attention机制总结
- 遍地开花的 Attention ,你真的懂吗?


- 本文作者: Jason
- 本文链接: https://caicaijason.github.io/2019/12/09/Transformer和注意力机制/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!